指数调样微服务改造总体设计方案
指数调样微服务改造
目录
证券交易所
指数调样微服务改造总体设计方案
简化版
领域驱动设计 、测试驱动开发,
需求永远是会变化的,就如同人必须呼吸;
而设计必须支撑变化,跟随需求。
阿里腾讯互联网早就开始了领域驱动设计;
而国企政府单位比较晚,但在信创项目改造开始后也引入了这一设计理念。
指数调样微服务改造前:
开发人员看不明白代码,实际看不懂业务,只能看明白代码、但不知道代码干什么、有什么业务逻辑; 好比只会英语单词,别人说的话听不懂,自己也说不清楚。
指数调样微服务改造后:
业务人员能懂,开发人员也能懂;
数据模型给开发设计人员使用的,而领域模型来源于业务,首先是从业务侧人员能理解,整个团队都能明白,需求设计一体不断演变进化,应对业务的复杂性和灵活多变。
 编辑
编辑
 编辑
编辑
 编辑
编辑
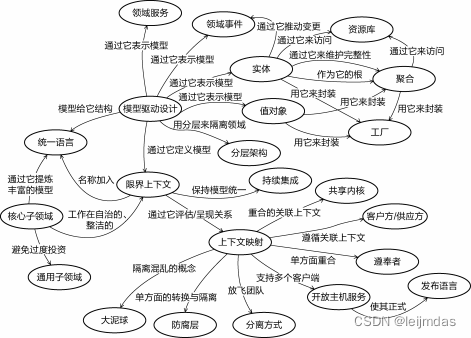
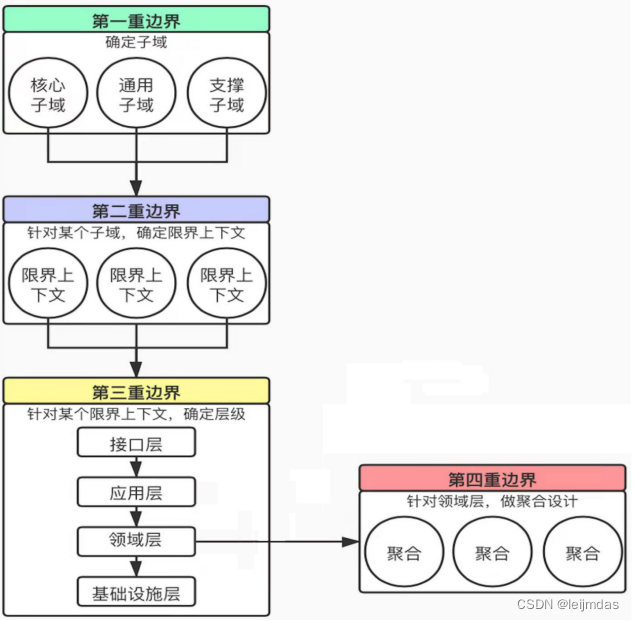
根据上图所示,我们通过四重边界来进行架构设计:
分而治之,领域驱动设计通过规划四重边界,把领域知识做了合理的固化和分层。业务有核心领域和支持域、业务域中又拆分成多个限界上下文(BC),一个BC中又根据领域知识核心与否进行分层,领域层中按照多个业务(子域)的强相关性进行聚合成一个子域。
【第一重边界】确定项目的愿景与目标,确定问题空间,确定核心子领域、通用子领域(多个子领域可以复用)、支撑子领域(额外功能,如数据统计、导出报表)
【第二重边界】解决方案空间里的限界上下文就是一道进程隔离层面的物理边界
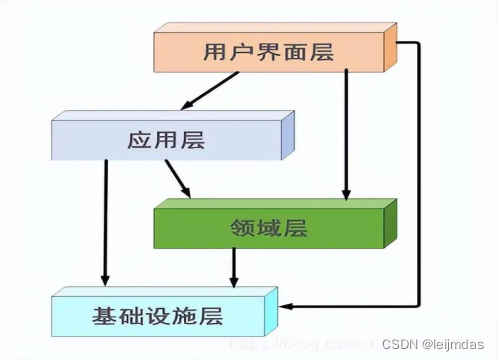
【第三重边界】每个限界上下文内,使用分层架构划分为:接口层、领域层、应用层、基础设施层之间的最小隔离。
【第四重边界】领域层里为了保证各个领域的完整性和一致性,引入聚合的设计作为隔离领域模型的最小单元。
 编辑
编辑
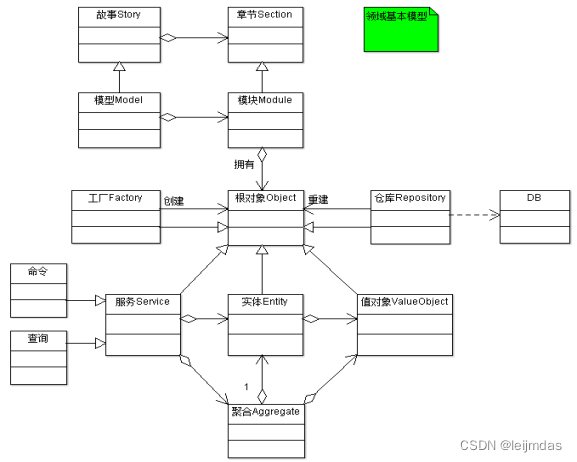
限界上下文(BoundedContext)
领域代表现实世界的特定问题和解决方案的集合,比如阳光E采、智慧运营。领域驱动设计里的限界上下文是对领域的软件实现,比如阳光E采就是采购领域内的限界上下文。限界上下文定义了解决方案的明显边界,边界里的每一个领域概念:包括领域概念内的属性和行为都有特殊含义。
实体(Entity)
实体与面向对象中的概念类似,在这里再次提出是因为它是领域模型的基本元素。在领域模型中,实体应该具有唯一的标识符,从设计的一开始就应该考虑实体,决定是否建立一个实体也是十分重要的。
值对象(Vaue Object)
值对象和我们说的编程中数值类型的变量是不同的,它仅仅是没有唯一标识符的实体,比如有两个收获地址的信息完全一样,那它就是值对象,并不是实体。值对象在领域模型中是可以被共享的,他们应该是“不可变的”(只读的),当有其他地方需要用到值对象时,可以将它的副本作为参数传递。
领域服务(Domain Service)
当我们在分析某一领域时,一直在尝试如何将信息转化为领域模型,但并非所有的点我们都能用Model来涵盖。对象应当有属性,状态和行为,但有时领域中有一些行为是无法映射到具体的对象中的,我们也不能强行将其放入在某一个模型对象中,而将其单独作为一个方法又没有地方,此时就需要服务。
服务是无状态的,对象是有状态的。所谓状态,就是对象的基本属性:高矮胖瘦,年轻漂亮。服务本身也是对象,但它却没有属性(只有行为),因此说是无状态的。
服务存在的目的就是为领域提供简单的方法。为了提供大量便捷的方法,自然要关联许多领域模型,所以说,行为(Action)天生就应该存在于服务中。服务具有以下特点:
a)服务中体现的行为一定是不属于任何实体和值对象的,但它属于领域模型的范围内
b)服务的行为一定设计其他多个对象
c)服务的操作是无状态的
不要随意放置服务,如果该行为是属于应用层的,那就应该放在那;如果它为领域模型服务,那它就应该存储在领域层中,要避免业务的服务直接操作数据库,最好通过DAO。
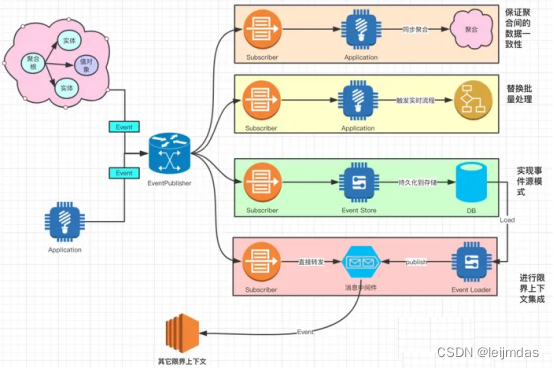
领域事件(Domain Event):
是将领域对象从对repository或service的依赖中解脱出来,避免让领域对象对这些设施产生直接依赖。领域事件的触发点在领域模型(domain model)中。就是当领域对象的业务方法需要依赖到这些对象时就发出一个事件,这个事件会被相应的对象监听到并做出处理。
使用领域事件来捕获发生在领域中的一些事情。
领域驱动实践者发现他们可以通过了解更多发生在问题域中的事件,来更好的理解问题域。这些事件,就是领域事件,主要是与领域专家一起进行知识提炼环节中获得。领域事件,可以用于一个限界上下文内的领域模型,也可以使用消息队列在限界上下文间进行异步通信。理解领域事件
领域事件是将领域对象从对repository或service的依赖中解脱出来,避免让领域对象对这些设施产生直接依赖。领域事件的触发点在领域模型(domain model)中。就是当领域对象的业务方法需要依赖到这些对象时就发出一个事件,这个事件会被相应的对象监听到并做出处理。
领域事件是领域专家所关心的发生在领域中的一些事件。
将领域中所发生的活动建模成一系列离散事件。每个事件都用领域对象表示。领域事件是领域模型的组成部分,表示领域中所发生的事情。
领域事件的主要用途:
保证聚合间的数据一致性
替换批量处理
实现事件源模式
进行限界上下文集成
 编辑
编辑
聚合(Aggregate)
聚合被看作是多个模型单元间的组合,它定义了模型的关系和边界。每个聚合都有一个根,根是一个实体,并且是唯一可被外访问的。正是如此,聚合可以保证多个模型单元的不变性,因为其他模型都参考聚合的根。所以要想改变其他对象,只能通过聚合的根去操作。根如果没有了,那么聚合中的其他对象也将不存在。customer是该聚合的根,其他的都是内部对象,如果外部需要用户地址,拷贝一份传递出去即可。显而易见,用户如果不存在,其他信息均无意义。
模块(Modue)
对于一个复杂的应用来说,领域模型将会变的越来越大,以至于很难去描述和理解,更别提模型之间的关系了。模块的出现,就是为了组织统一的模型概念来达到减少复杂性的目的的。而另一个原因则是模块可以提高代码质量和可维护性,比如我们常说的高内聚,低耦合就是要提倡将相关的类内聚在一起实现模块化。
模块应当有对外的统一接口供其他模块调用,比如有三个对象在模块a中,那么模块b不应该直接操作这三个对象,而是操作暴露的接口。模块的命名也很有讲究,最好能够深层次反映领域模型。
资源库(Repository)
资源库封装了获取对象的逻辑,领域对象无须和底层数据库交互,它只需要从仓库中获取对象即可。仓库可以存储对象的引用,当一个对象被创建后,它可能会被存储到仓库中,那么下次就可以从仓库取。如果用户请求的数据没在仓库中,则会从数据库里取,这就减少了底层交互的次数。
工厂(Factory)
在大型系统中,实体和聚合通常是很复杂的,这就导致了很难去通过构造器来创建对象。工厂就决解了这个问题,它把创建对象的细节封装起来,巧妙的实现了依赖反转。当然对聚合也适用(当建立了聚合根时,其他对象可以自动创建)。工厂最早被大家熟知可能还是在设计模式中,的确,在这里提到的工厂也是这个概念。
但是不要盲目的去应用工厂,以下场景不需要工厂:
a)构造器很简单
b)构造对象时不依赖于其他对象的创建
c)用策略模式就可以解决
测试驱动开发的基本思想就是在开发功能代码之前,先编写测试代码,然后只编写使测试通过的功能代码,从而以测试来驱动整个开发过程的进行。这有助于编写简洁可用和高质量的代码,有很高的灵活性和健壮性,能快速响应变化,并加速开发过程。
测试驱动开发的基本过程如下:
① 快速新增一个测试
② 运行所有的测试(有时候只需要运行一个或一部分),发现新增的测试不能通过
③ 做一些小小的改动,尽快地让测试程序可运行,为此可以在程序中使用一些不合情理的方法
④ 运行所有的测试,并且全部通过
⑤ 重构代码,以消除重复设计,优化设计结构
简单来说,就是不可运行/可运行/重构——这正是测试驱动开发的口号。
重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
重构(动词):使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
重构原则:不改变原有功能,要有单元测试用例。
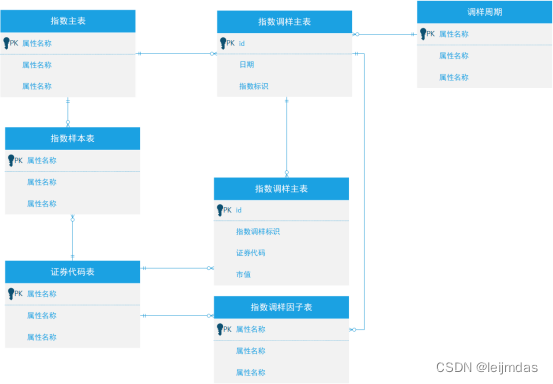
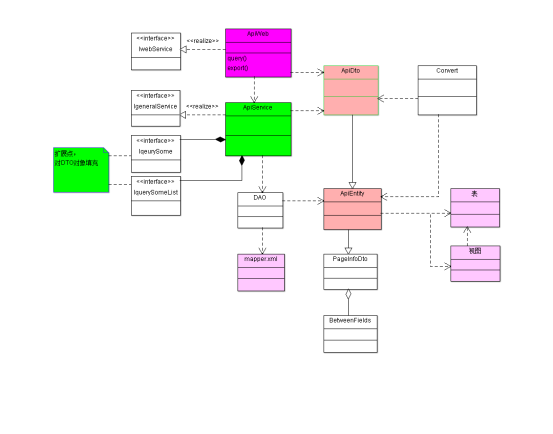
指数调样数据模型
 编辑
编辑
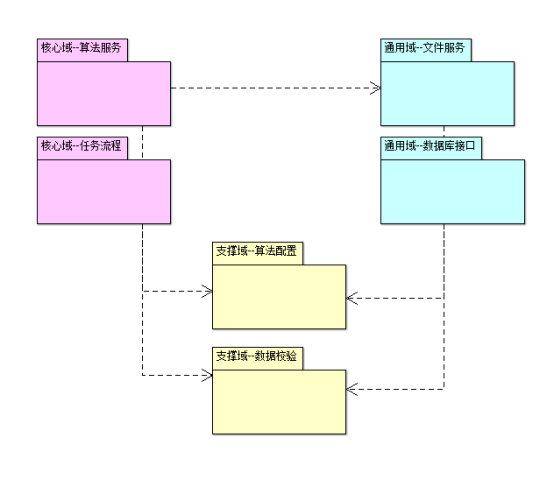
指数调样领域模型
 编辑
编辑
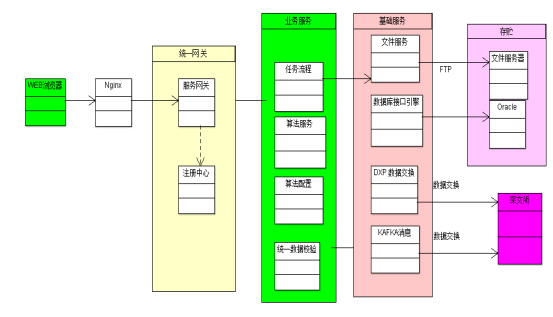
指数调样总体技术架构
 编辑
编辑
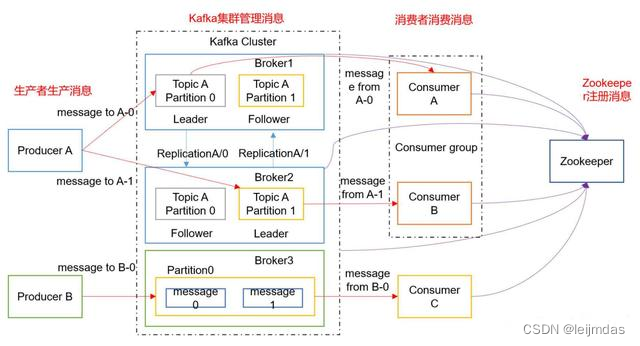
卡夫卡消息架构
 编辑
编辑
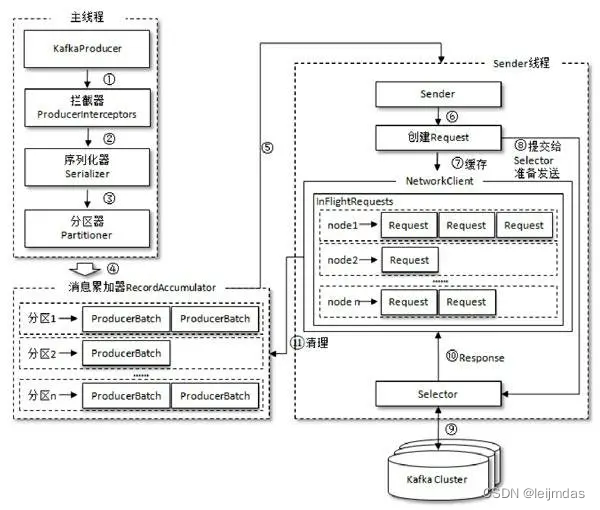
卡夫卡生产者原理
 编辑
编辑
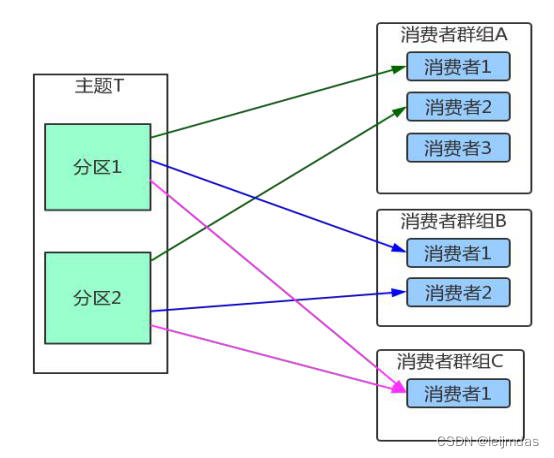
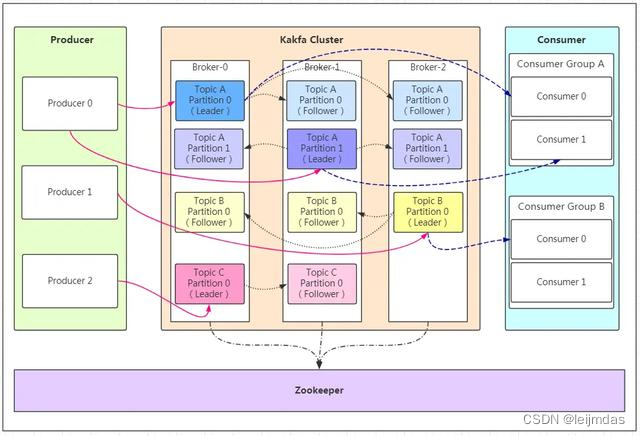
卡夫卡消费者原理
 编辑
编辑
 编辑
编辑
生成代码结构如下
 编辑
编辑
规则引擎
脚本化配置业务规则。
组件定义统一: 所有的逻辑都是组件,为所有的逻辑提供统一化的组件实现方式,小身材,大能量。
规则轻量: 基于规则文件来编排流程,学习规则入门只需要5分钟,一看既懂。
规则多样化: 规则支持xml、json、yml三种规则文件写法方式,喜欢哪种用哪个。
任意编排: 再复杂的逻辑过程,利用LiteFlow的规则,都是很容易做到的,看规则文件就能知道逻辑是如何运转的。
规则持久化: 框架原生支持把规则存储在标准结构化数据库,Nacos,Etcd,Zookeeper,Apollo,redis。您也可以自己扩展,把规则存储在任何地方。
优雅热刷新机制: 规则变化,无需重启您的应用,即时改变应用的规则。高并发下不会因为刷新规则导致正在执行的规则有任何错乱。
支持广泛: 不管你的项目是不是基于Springboot,Spring还是任何其他java框架构建,LiteFlow都能游刃有余。
JDK支持: 从JDK8到JDK17,全部支持。无需担心JDK版本。
Springboot支持全面: 支持Springboot 2.X到最新的Springboot 3.X。
脚本语言支持: 可以定义脚本语言节点,支持Groovy,Javascript,QLExpress,Python,Lua,Aviator,Java。未来还会支持更多的脚本语言。
脚本和Java全打通: 所有脚本语言均可调用Java方法,甚至于可以引用任意的实例,在脚本中调用RPC也是支持的。
规则嵌套支持: 只要你想的出,你可以利用简单的表达式完成多重嵌套的复杂逻辑编排。
组件重试支持: 组件可以支持重试,每个组件均可自定义重试配置和指定异常。
上下文隔离机制: 可靠的上下文隔离机制,你无需担心高并发情况下的数据串流。
声明式组件支持: 你可以让你的任意类秒变组件。
详细的步骤信息: 你的链路如何执行的,每个组件耗时多少,报了什么错,一目了然。
稳定可靠: 历时2年多的迭代,在各大公司的核心系统上稳定运行。
性能卓越: 框架本身几乎不消耗额外性能,性能取决你的组件执行效率。
自带简单监控: 框架内自带一个命令行的监控,能够知道每个组件的运行耗时排行。
什么场景适用
LiteFlow是一款编排式的规则引擎,最擅长去解耦你的系统,如果你的系统业务复杂,并且代码臃肿不堪,那LiteFlow框架会是一个非常好的解决方案。

 成员
成员 - 成交数 --
- 成交额 --
- 应答率