小朋友都能懂的人工智能⓹-不可思议的大模型
「 15 神奇参数替代了海量数据」
L:上回我们说到了大语言模型ChatGPT,提到它能“创造”李白的《静夜思》而非背诵,大家有些难以置信了,是吧。
A爸:是的,我现在依然认为您在开玩笑,我认为《静夜思》肯定是存在于ChatGPT内部的数据中,或者就是它上网搜的。
B爸:会不会这样,当你和它随意聊天对话时,它的回复是一种创造。当你问及史料诗歌这类记载时,他就搜资料来回答你。
L:B爸说的似乎有理,有中庸之道的感觉。
众笑。
L:事实上不只是《静夜思》,任何知识类的问题它都能对答如流,如果数据都存在其内部,那ChatGPT存储的内容得覆盖绝大部分的网页文本、书籍、维基百科、科学论文、社交媒体、专业文献、新闻、报告....才能做得到。问题来了,这可是要存储海量数据啊。
B爸:这么庞大的数据来源,数据海量不是很正常吗,有什么问题吗?
L:你是直接连接大模型官网进行在线访问的,这种方式个人使用尚可接受,而企业客户出于数据安全性、自主可控性等因素,则无法接受,所以企业会选择本地私有化部署,实际上各主流大模型也都支持这种部署方式。大家思考一下,我说这段话想表达什么意思?
A爸:我明白了!如果大模型在企业是本地部署,按照之前我们的认知,就意味本地要有这些海量数据,那存储成本必然惊人。大模型也就难以在企业落地了。

L:A爸说的太对了!现在大家还会觉得ChatGPT自带海量基础数据吗?
A爸:如此说来,ChatGPT是真不太可能去存储这些海量基础数据了。
L:A爸,你想通了啊,现在相信ChatGPT是自己“创造”出《静夜思》了吧。
A爸:从推理上我相信了,可怎么做到呢,感觉像变魔术。
A:会不会这样,ChatGPT只存一部分基础数据,这样存储空间就不大了?
L:又来一个中庸之道。
众笑。
L:小A啊,基础数据要么就都存,要么就都不存,存一部分就意味着很多数据会查不到,这还能叫通用人工智能吗?
至此,众人都相信了。不过,大家依然觉得不可思议。
L:接下来,我问问ChatGPT4,看看它是如何回答的,好不好?
众人非常期待! L老师当即调出ChatGPT4进行问答,很快结果出来了,如下。

看到ChatGPT自己承认了既不是上网搜的,也不是因为数据库中保存了这首诗后调用的,这下大家彻底信了。
L:其实从某种意义上来说,网页文本、书籍等这些海量基础数据也可以说成是ChatGPT的一部分,所以这些基础数据也可以称之为训练数据。只是ChatGPT训练完毕正式启用时,它就不再需要这些训练数据了。
然而,正是基于海量基础数据的训练,ChatGPT内部产生了许多神奇的参数,这些参数的数据规模相比训练数据的数据规模而言,微乎其微,不过作用惊人。
换句话说,让ChatGPT写出《静夜思》,不是因为它读取原诗的内容,而是它在通过基于各种参数的计算分析统计后顿悟了,于是刷刷刷,写出来了。
A爸:神奇参数替代了海量数据!
L:是的,就是这么神奇。对了,A爸,你还记得上一次你说过的话吗,你认为ChatGPT是在得到人类大量知识的投喂后,就能做到随时从数据库中调取调出知识来和人类交流。
A爸:记得,您说我既对又不对。我明白为什么了。知识投喂更准确的应该是知识训练,调取出知识更准确的应该是训练出参数。
L:完美,给A爸点赞!
「 16 语言与神经网络一样是分层的」
L:作为大语言模型,首要任务就是要理解人类语言,大家觉得ChatGPT是如何做到的?
C妈:是不是它博览群书后,自然而然就理解了,学的越多理解的越深。
L:C妈回答基本正确。我们人类语言是分层的,随着一个人从小长大,他的阅读量越来越多,社会实践也越来越多,那么他从语言中可以读出的信息量也就越来越丰富,洞察力也越来越深,对事物的判断和预测也越来越准。
同样的,随着ChatGPT版本不断迭代,网络规模越来越大,它可识别的特征层级也越来越深。
C:L老师,语言都有哪些层级啊。
L:最基本的是语法、语义;接着是语气、风格、情绪;然后是语言背后的意图、偏好;进一步到文化、心理;以及更进一步的价值观、意识形态等底层的社会学特征等等。

C妈:L老师您这么一说,还真是如此,我感觉我的回答有些肤浅了。ChatGPT就是一个机器,它能实现这么深刻的分层认知吗?
L:大家还记得卷积神经网络吗,我提到过分层的结构。包括如何逐层细化识别出猫,以及如何通过识别棋局形成价值网络和策略网络的过程。
A爸:记得,您提到卷积神经网络分为输入层、隐藏层和输出层,其中隐藏层可以有多层。
L:是的,我们一般把隐藏层超过3层的神经网络也称之为深度学习。大家注意到没,理解人类语言其实和认识猫、AlphaGo下棋本质无区别,都是逐层提取特征最后完成输出。比如猫的轮廓、毛发、脸型、耳朵,胡子、尾巴......比如围棋的死型、活型、外势、实地、危险、安全、厚、薄、气、目数......比如人类语言的语法、语义、语气、风格、情绪、意图、偏好、文化、心理、价值观、意识形态....
更多细节可参考OpenAI论文《Language Models are Few-Shot Learners》。
A:有趣,原来语言与神经网络一样是分层的。
L:是的,大道至简,万事相通。看上去完全不同的图像识别、下棋、人类语言理解,本质居然是一样的,都是多层特征提取,都能用基于神经网络的架构解决问题。
C妈:L老师,ChatGPT对语言的理解比我们人类更厉害了吗?
L:从ChatgGPT4展现出来的语言理解能力来看,确实已远超大部分人,后续我会和大家一起感受感受。
A爸:ChatGPT能从这么多维度来理解语言,这水平不高都不行啊。
L:是的。这里我再强调一些,这些维度只是一种易于理解的类比,实际维度并非我们人类所能理解的,当然了,其维度的数量更是惊人。
A爸:L老师,您说的让我茅塞顿开!不过语言的文字组合是天文数字,每种组合含义又各不相同,理解人类语言难度不小吧,具体该如何实现呢?
L:ChatGPT的语言理解从宏观层面看,和猫的识别、AlphaGo下棋等几无差异。但是具体落到实现的细节处,却是有着天壤之别。
「 17 向量化是理解语言的第一步」
L:ChatGPT是如何做到看见一句话,就能准确理解其意思呢?这里至少需要两步,第一步叫向量化,第二步叫信息压缩与特征提取,我们先来看向量化。
B: 什么是向量化?
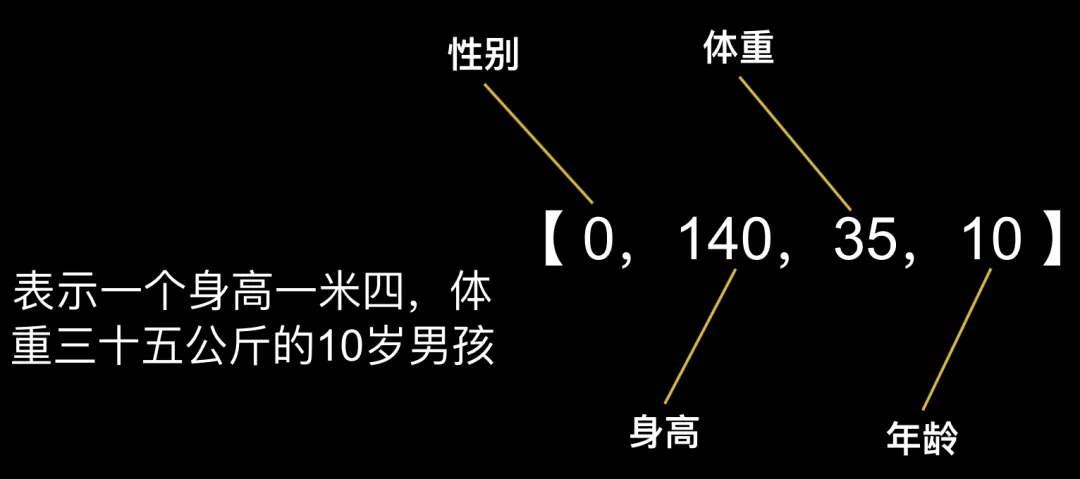
L:简答来说,就是要把你要表示的东西变成一组数字的组合。比如我们要表示一个人,可以用这样一组数字:【0,140,35,10】来表达。
B:这啥意思啊。
L:假设第一个数字表示性别,0是男,1是女,第二个数字表示身高,第三个数字表示体重,第四个数字表示年龄。小B你知道是啥意思了吗?
B:表示一个身高一米四,体重三十五公斤的10岁男孩,咦,这不就是我吗?
L:哈哈,如果你觉得可能还不一定是你。我们可以增加更多的维度,比如【性别,身高,体重,年龄,胸围,腰围,臀围,体脂率,血压,视力,爱好,特长,年级,学校,城市....】而这些都可以表示成数字,维度越多,对一个人的定义就越准确。
A爸:那为什么要向量化呢?
L:一方面是向量化能表示成数字,方便电脑处理,更重要的是,向量化以后的空间结构,能很好的展示出规律。我们仅以身高和体重两个维度形成坐标系来举例说明。如下图所示,所有与【140,35】坐标接近的位置,就是体型和小B相似的人。比如身高1米42,体重36公斤的小A就距离小B很近。而身高185,体重80公斤的A爸,则距离小B很远。
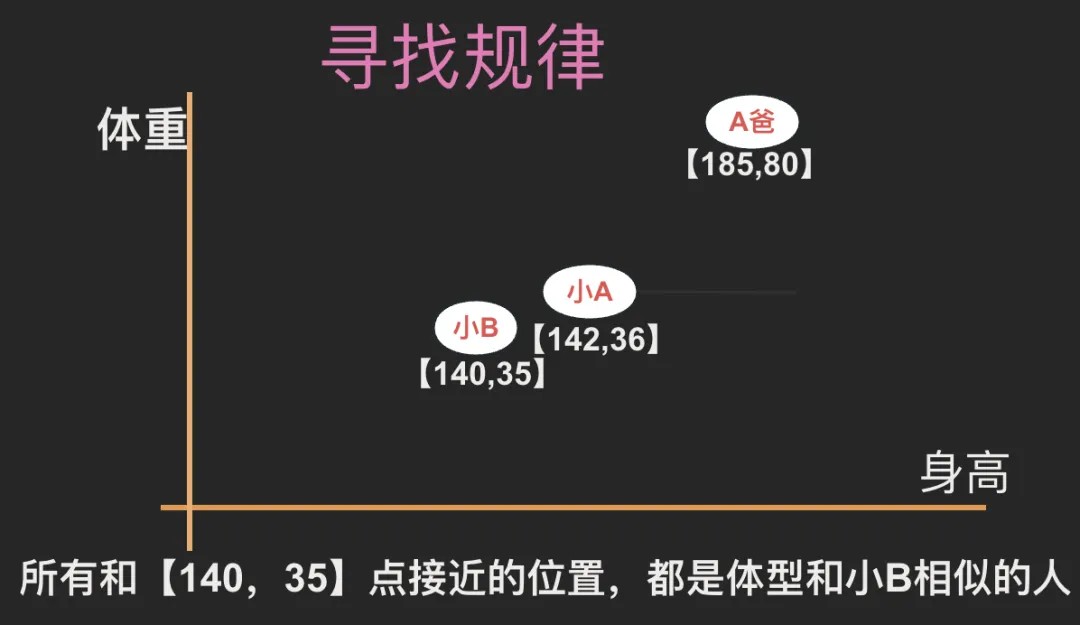
我们可以增加更多的维度,比如增加年龄,就变成三维坐标系,再增加性别,就变成四维坐标系...衡量的标准就越多,维度越多。在多维坐标系里,我们就能更多的通过空间关系理解每一个人的特征。大家能听明白吗?
如此通俗易懂,众人纷纷点头。
L:接下来引出关键之处了,大家想想,其实词语也是一样的。如果我们把词语放在一个高纬坐标里,意义相近的词语,空间就会更近。
比如“美”和“好”。从词性维度上,它们都是形容词。从贬义褒义上它们都是褒义,从使用场景上,它们经常一起出现....还有各种我们猜不出来的维度,所有这一切维度让它们在一个高维坐标里,出在了比较近的距离。
A爸:有意思,原来是这样啊。
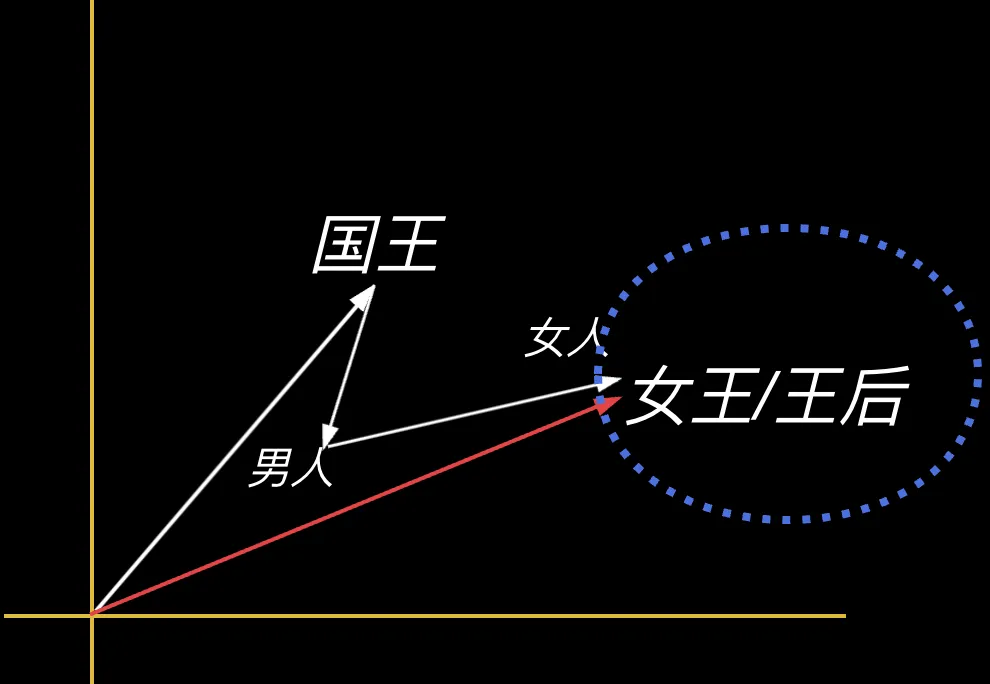
L:还有更有意思的,因为向量是可计算的,可相加相减相乘,当我们把词语放到向量空间后,我们发现神奇的事发生了,“国王”这个词减去“男人”再加上“女人”,得出的向量居然和“女王”或者“王后”的位置非常接近,这说明在一个合适维度的坐标中,词语之间的空间关系反映了它们现实世界的实际关系。
A爸:这么神奇啊!
L:不过向量化说起来似乎很简单,不过实现起来,可不那么容易哦。
「 18 如何完成向量化工作」
L:前面说了,我们需要把词语放到一个合适维度的坐标中,还要能正确的标注出每个词语在这个空间中的位置,神奇的事才能发生。但是怎么才能找到这些维度,怎么找到词语的空间位置呢,这就需要训练了。
具体如何训练,举例说明。我们预先准备一个多维坐标。准备10000个词,把这10000个词随便扔到坐标里,也就是随机产生每个词的向量,如下图所示。
 此时我们到语料库中取出语料,让机器玩词语接龙。比如《三国演义》的第一句,“话说天下大势,分久必合,合久必分。周末七国分争,并入于秦。”
此时我们到语料库中取出语料,让机器玩词语接龙。比如《三国演义》的第一句,“话说天下大势,分久必合,合久必分。周末七国分争,并入于秦。”
机器见到这句话后大喜过望,赶忙去自己的向量空间去找到第一个词“话“和第二个词”说“,把它们的向量拿过来一通计算,看看第二个词跟在第一个词背后的概率有多大,结果算出来概率很小,说明一开始随便放的位置不合适。
 怎么办?那赶紧调整呗,经过不断尝试后最终调整好了词的位置。
怎么办?那赶紧调整呗,经过不断尝试后最终调整好了词的位置。 接着把第三个词“天”加进去继续训练,接着是第四个词“下”,第五个词“大”....就这样机器读完了三国、水浒、红楼梦、西游记....
接着把第三个词“天”加进去继续训练,接着是第四个词“下”,第五个词“大”....就这样机器读完了三国、水浒、红楼梦、西游记....

在足够多的语料的训练下,这10000个词都被反复训练了无数次。终于,每个词都找到了自己在坐标里的正确位置。至此,词的向量化工作终于完成了。
更多细节可参考OpenAI论文《Training language models to follow instructions with human feedback》。
A爸:这下我是算搞明白了,原来是这样啊!
L:10年前Google就发布了著名的word2vec模型,详见《Efficient Estimation of Word Representations in Vector Space》。不过既然词向量已经帮机器理解每个词的意思,为什么大模型到今天才发展起来?
众人纷纷摇头。
L:那是因为我们只干了第一步向量化,之前提到的第二步还没做。那就是信息压缩与特征提取。没有做特征提取,就相当于没有找到正确的规律,用错误的规律去训练电脑,最后电脑找到的词向量也就是错误的。
A爸:换句话说,这些词其实并没有找到自己在向量空间中的正确位置。
L:是的。
A爸:具体该如何进行信息压缩与特征提取?
L:精彩程度让人拍案叫绝!细节可参考Google论文《Attention Is All You Need》。时候不早了,咱们下回分解吧。

 成员
成员 - 成交数 --
- 成交额 --
- 应答率