还在用 ELK?你已经 Out 了
ELK 的背景和现状
在技术方案选择仍然受限的时候,Elasticsearch 依靠出色的全文搜索能力,成为了日志存储和查询方案的首选。随后,elastic.co 围绕 Elasticsearch 打造了 ELK 生态,提供了完整的采集、存储、分析生态,后续补充的 beats 组件家族[1]更是完善了采集上的短板,使得数据采集更加灵活和轻量化。至此 ELK 几乎成为了日志采集方案的标准答案。
时间来到 2025 年,各种新的编程和部署范式开始被大规模地理解和采纳。对比更加现代的方案,Elasticsearch 相对老旧的技术选择和架构设计逐渐展现出一些弊端:
1. 存储成本飞涨:日志越多,代价越大
随着软件系统的复杂性提升,应用程序输出的日志数量正以指数级增长。为了排查根因,我们往往需要尽可能保留全部日志。但 Elasticsearch 为了加快全文搜索,会为每一行日志构建索引,这也意味着巨大的存储开销。
我们测试发现:写入 10GB 的日志数据,Elasticsearch 反而生成了 超过 10GB 的存储文件。长期保存日志数据,存储成本成了 ELK 被替换的第一主因。
2. 存算耦合,资源浪费严重
作为诞生于云计算前的系统,Elasticsearch 天然采用本地磁盘存储,并内置多副本机制。结合上面提到的庞大数据量,这就意味着对高性能 SSD 的依赖也水涨船高。
更糟的是,存储与计算资源绑定在一起:你想扩容 CPU 来应对高并发,就得连着扩磁盘;反之亦然。结果就是——你用不上,但你得买单。
3. 吃资源,还爱 OOM
运行在 JVM 上的 Elasticsearch,对硬件资源,尤其是内存的需求相当“饥渴”。在各种论坛中,“OOM 被 kill”的相关讨论随处可见。在生产环境中,基本上都需要用非常高规格的机器来运行 Elasticsearch。
横向对比多个日志数据库后我们发现:在相同的写入量级下,Elasticsearch 的硬件资源消耗是最高的(前提是它还能撑得住这个量级不挂)。
4. 运维复杂,云原生不友好
如果说 Elasticsearch 有什么“名声”,那大概是它的运维难度了。
启动单节点或许轻松,但当你开始面临升级、扩容、故障恢复、备份等场景,每一步都让人头大。更别提想把 Elasticsearch 交给 Kubernetes 管理——自动化体验几乎无从谈起。
虽然 ELK 曾风靡一时,现在依然是很多用户日志监控方案的选择。但经过以上分析,可以显而易见地发现 ELK 已经逐渐跟不上高写入量和长期存储的日志实时监控和数据分析的需求了。
我们迫切需要一个更现代化、低成本、容易运维的日志监控方案。
GreptimeDB 作为日志监控存储
GreptimeDB 是一款针对可观测性数据设计的云原生数据库,适用于可观测性数据、指标记录和实时监控工作负载,其架构针对高频率、时间戳数据(例如指标和事件)的写入和查询进行了优化。
作为云原生数据库,GreptimeDB 采用了计算与存储分离的架构。它基于 Kubernetes 进行部署,可实现无缝的弹性扩展,非常适合云环境。资源独立扩展支持更高的成本效率和灵活性,确保高需求场景下性能稳定;无需手动干预的设计是 GreptimeDB 在观测性等特定场景中的显著优势。
相较传统方案,GreptimeDB 的存算分离架构和云原生设计,让它成为一个非常适合日志存储的现代时序数据库。以下是它在实际使用中带来的核心优势:
1. 极高压缩率,节省存储就是省钱
GreptimeDB 采用列式存储结构,并结合游程编码、字典编码等方式,在日志场景下实现了极高的数据压缩效果。
我们实测发现:相同日志写入量下,GreptimeDB 的存储文件大小大约是 Elasticsearch 的 1/10——存得多,占得少。
2. 存算分离,存储成本更进一步下降
GreptimeDB 从设计之初就采用存算分离架构,数据存储在对象存储中,既省钱又省心:
在 AWS 等云服务中,对象存储的价格通常不到块存储的一半;
存储可靠性由底层对象存储保障,减少了数据库自身做多副本和备份的复杂度;
没有容量限制,也不用为扩容 CPU 而被迫同步扩容磁盘,告别资源浪费。
3. 轻量运行,硬件要求更低
GreptimeDB 由 Rust 编写,系统资源占用更少,即使在轻量硬件上也能稳定运行。
在我们的测试中,在相同写入量下,Elasticsearch 的 CPU 和内存占用是 GreptimeDB 的数倍。对于日志系统来说,这意味着更少的 OOM,更好的稳定性。
4. 云原生运维,轻松托管上云
得益于云原生架构,GreptimeDB 在 Kubernetes 上的部署和运维体验非常流畅:
GreptimeDB 云原生的架构设计使得其部署在 Kubernetes 环境上非常简单,部署后能够自动地完成滚动发布、停机重启、资源变更、负载均衡等运维操作,在用户只需少量介入甚至不介入的情况下也可以稳定地运行。对于运维团队来说,这是真正的省心省力。
5. 多样化的索引机制,加速查询性能
GreptimeDB 提供了多种索引类型,以适配不同场景下的查询需求:
对于低基数的数据(如
k8s_pod_ip),可以使用倒排索引,加速过滤操作;对于高基数的文本(如
trace_id),可以设置跳数索引,提升精确查询的效率;对于文本的模糊搜索,可以在字段上设置全文索引,支持灵活的搜索能力。
通过索引的灵活组合,在降低构建和存储索引开销的前提下,显著提升查询速度。更详细的索引介绍可以参考这篇文档[2]。
使用 Vector + GreptimeDB 作为日志监控方案
接下来,我们会介绍如何使用 Vector 和 GreptimeDB 快速搭建一个日志采集和存储方案。
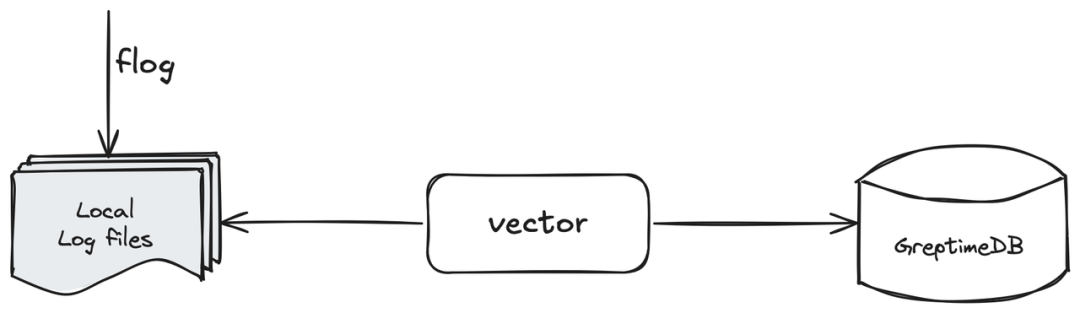
(图 1:Vector 和 GreptimeDB 结合的日志监控方案)
在这个简单的方案介绍中,我们使用:
Flog 来
mock生成本地日志文件;Vector 采集本地日志文件,并写入 GreptimeDB 实例中;
使用 GreptimeDB 自带的
logview或者其他工具来查看写入的日志行。
Mock 日志文件
我们使用 flog[3]来模拟生成一个不断写入的日志文件。通过以下命令,即可快速生成一个每秒写入一行日志的日志文件 log.txt:
flog -o log.txt -t log -l -d 1
在实际的生产环境中,应用程序会用过 logging 库将日志输出到日志文件。日志文件可能有一些时间后缀,并且可能根据规则进行自动切分和轮换。对于一些流行的框架,Vector 还集成了日志采集逻辑,例如 kubernetes logs[4]:
执行 head -1 log.txt 来查看日志数据的样例:
17.61.197.240 - nikolaus3107 [14/Apr/2025:21:11:44 +0800] "HEAD /envisioneer/efficient HTTP/1.0" 406 5946
部署 GreptimeDB 实例
我们需要部署一个 GreptimeDB 实例,本文以一个单点实例为例;单点实例和集群实例都对数据入口的 API 保持一致。一般在生产环境中需要部署集群,可以参考这篇文档[5]。
安装 GreptimeDB 比较简单,不同的安装方式可以参考这篇文档[6]。为了方便在各个环境下复现,使用 docker 的方式启动 GreptimeDB 数据库:
docker run -p 127.0.0.1:4000-4003:4000-4003 \ --name greptime --rm \ greptime/greptimedb:v0.14.0-nightly-20250407 standalone start \ --http-addr 0.0.0.0:4000 \ --rpc-bind-addr 0.0.0.0:4001 \ --mysql-addr 0.0.0.0:4002 \ --postgres-addr 0.0.0.0:4003
然后通过执行 curl 127.0.0.1:4000/health 来验证数据库是否已经成功启动;也可以通过 mysql -h127.0.0.1 -P4002 使用 MySQL 客户端连接到数据库进行确认。
使用 Vector 采集日志
我们需要先安装 Vector,可以参考这个官方文档[7]。
推荐使用系统自带的包管理器[8]来完成安装,简单方便。安装完成后,可以通过运行 vector --version 来验证是否安装成功。本文中我们将通过本地启动 Vector 来采集日志数据,对于真实环境下的 Vector 部署,可以参考这篇博客[9]。
Vector 配置介绍
接下来,我们需要编写采集日志所需的 Vector 配置。示例如下:
# config.toml [sources.file_input] type = "file" include = [ "<path_to_log_dir>/log.txt" ] data_dir = "<data_dir>" [sinks.greptime_sink] type = "greptimedb_logs" inputs = [ "file_input" ] compression = "gzip" dbname = "public" endpoint = "http://127.0.0.1:4000" pipeline_name = "greptime_identity" table = "app_log"
让我们分别来看下这个配置内容:
[sources.file_input] type = "file" include = [ "<path_to_log_dir>/log.txt" ] data_dir = "<data_dir>" ignore_checkpoints = true
这一部分是 Vector 的 File Source[10],Source 是 Vector 的数据输入端,可以从各种适配的来源采集数据。我们通过 type = "file" 指定使用 File Source,include 选项用于配置文件地址(include 可以使用通配符配置多个日志文件,见文档[11]。最后我们需要配置 data_dir 来指定一个元数据目录,Vector 默认的路径是 "/var/lib/vector/":
[sinks.greptime_sink] type = "greptimedb_logs" inputs = [ "file_input" ] compression = "gzip" dbname = "public" endpoint = "http://127.0.0.1:4000" pipeline_name = "greptime_identity" table = "app_log"
这一部分就是 GreptimeDB logs sink[12]。Sink 是 Vector 的数据输出端,将数据发送到适配的输出端。我们通过 type= "greptimedb_logs" 指定使用 GreptimeDB 日志输出,inputs 指定接收上面的 File Source 输入。这里的配置基本上只是指定了 GreptimeDB 的链接参数:
compression指定了数据发送的压缩参数;dbname指定写入的数据库,在这里我们写入到默认的public数据库;endpoint指定了 GreptimeDB 的 HTTP 端口,上文中我们通过docker启动了 ;GreptimeDB 实例,并且将数据库的 4000 端口绑定到了本地host;pipeline_name指定了日志写入的 Pipeline[13],Pipeline 是 GreptimeDB 提供的内置对文本数据预处理的一个机制。在这里我们使用greptime_identity[14],即不对原始数据做处理,直接将输入的 JSON 数据原样分列存到数据库中;table指定了我们需要将数据写到哪一张数据库表中。如果这张表目前还不存在则会进行自动建表。
将日志写入 GreptimeDB
配置之后就可以将文件中的日志数据写入 GreptimeDB。运行以下命令即可使用配置启动 Vector:
vector -c <path_to_config_file>
如果看到以下日志数据,并且没有看到 ERROR 日志,就可以确认 Vector 已经开始正常往 GreptimeDB 中写入数据了:
2025-04-15T06:53:17.864603Z INFO vector::topology::builder: Healthcheck passed.
在 GreptimeDB 中查询数据
接着,我们可以通过查询 GreptimeDB 来验证数据写入成功。使用 MySQL 客户端运行 mysql -h127.0.0.1 -P4002 即可连接到数据库。
首先执行 show tables; 来观察表是否成功创建:
+---------+ | Tables | +---------+ | app_log | | numbers | +---------+ 2 rows in set (0.018 sec)
然后执行 select * from app_log limit 2; 来观察数据:
+----------------------------+------------------------+-----------+------------------------------------------------------------------------------------------------------------------+-------------+--------------------------------+ | greptime_timestamp | file | host | message | source_type | timestamp | +----------------------------+------------------------+-----------+------------------------------------------------------------------------------------------------------------------+-------------+--------------------------------+ | 2025-04-15 07:02:37.136667 | <path_to_file>/log.txt | some_host | 17.61.197.240 - nikolaus3107 [14/Apr/2025:21:11:44 +0800] "HEAD /envisioneer/efficient HTTP/1.0" 406 5946 | file | 2025-04-15T07:02:36.116847265Z | | 2025-04-15 07:02:37.136674 | <path_to_file>/log.txt | some_host | 56.87.252.7 - - [14/Apr/2025:21:11:45 +0800] "PATCH /bricks-and-clicks/transition/interfaces HTTP/1.1" 416 15579 | file | 2025-04-15T07:02:36.116864203Z | +----------------------------+------------------------+-----------+------------------------------------------------------------------------------------------------------------------+-------------+--------------------------------+ 2 rows in set (0.032 sec)
可以看到,除了 message 列中保存了 mock 生成的日志之外,还多了几列内容:
greptime_timestamp:由于我们使用了greptime_identity且没有指定时间索引列(greptime_identity模式下也可以手动指定索引列,见文档[15]),所以 GreptimeDB 会记录日志到达服务端的时间,并将其设置为时间索引列。通常我们更希望时间索引反映的是日志的实际产生时间,以便更准确地还原事件发生的顺序;file、host、source_type、timestamp:细心的读者可能已经发现了,这些是 Vector 自动附加的元信息。如果不手动删除,Vector 默认在输出时包含这些运行时的上下文信息。
通过 log-query 查看数据
GreptimeDB 自带了一个 dashboard 界面,可以方便地执行数据查询和操作。在浏览器中输入 http://127.0.0.1:4000/dashboard/#/dashboard/log-query 即可快速打开 log-query 页面:
(图 2: Log-Query 访问界面)
点击 Table 的下拉菜单,我们可以看到刚才创建的 app_log 表名。点击选中 app_log 表,然后点击上方的 run 按钮,就可以在 log-query 中查看到刚才写入的日志数据:
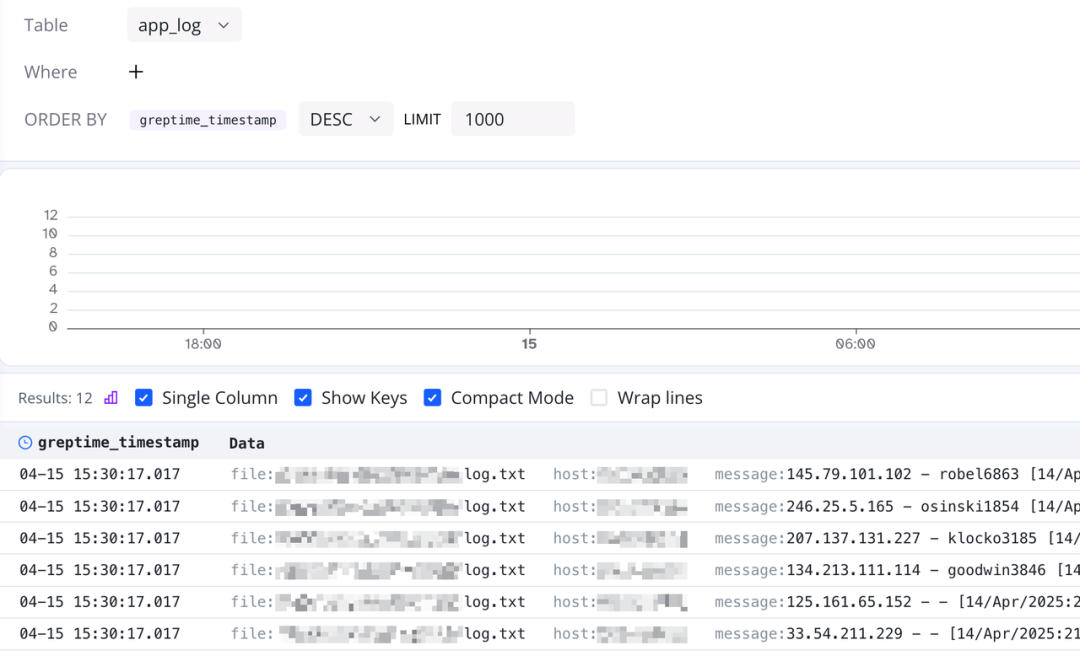
(图 3:查看已写入的日志数据)
使用 Pipeline 解析日志
在上一个环节中,我们已经成功运行 Vector,将日志数据从文件中采集后并写入到 GreptimeDB。不过我们此时是原样采集整个日志行,并将其作为单列写入数据库。这样一来,如果需要筛选某类日志,只能依赖 LIKE 模糊查询,不仅效率低下,也不利于后续分析。
在生产环境中,日志一般先通过 ETL 流程进行预处理,将日志拆解为结构化字段后再入库。上文提到了 GreptimeDB 内置 Pipeline 机制,用来预处理日志文本数据。
接下来,我们介绍如何通过 Pipeline 将日志文本进行解析,来提高日志的使用效率。
编写 Pipeline 配置
首先,在使用 Pipeline 前需要先编写配置并保存到数据库中,供 GreptimeDB 在运行时调用。Pipeline 通常根据输入的文本数据进行编写,以输入的 mock 日志文本为例,编写如下 Pipeline 配置:
# pipeline.yaml
processors:
-dissect:
fields:
-message
patterns:
-'%{client_ip} - %{user_identifier} [%{timestamp}] "%{http_method} %{request_uri} %{http_version}" %{status_code} %{response_size}'
ignore_missing:true
-date:
fields:
-timestamp
formats:
-'%d/%b/%Y:%H:%M:%S %z'
timezone:'Asia/Shanghai'
ignore_missing:true
transform:
-fields:
-client_ip
-user_identifier
type:string
index:skipping
-fields:
-http_method
-http_version
type:string
index:inverted
-fields:
-request_uri
type:string
index:fulltext
-fields:
-status_code
type:int32
-fields:
-response_size
type:int64
-fields:
-timestamp
type:time
index:timestampPipeline 主要由 processors 和 transform 两部分组成,前者对数据进行处理,后者将处理后的字段转换成数据库识别的数据类型 。下面我们对 Pipeline 配置的每部分进行介绍:
processors:
-dissect:
fields:
-message
patterns:
-'%{client_ip} - %{user_identifier} [%{timestamp}] "%{http_method} %{request_uri} %{http_version}" %{status_code} %{response_size}'
ignore_missing:true
-date:
fields:
-timestamp
formats:
-'%d/%b/%Y:%H:%M:%S %z'
timezone:'Asia/Shanghai'
ignore_missing:true首先使用 dissect processor 把字段从长文本中提取出来,根据空格划分可以提取出 client_ip、user_identifier 等字段。然后使用 date processor 将时间文本转换为 timestamp 数据类型,这里需要指定一个解析的 format 和 timezone 信息:
transform: -fields: -client_ip -user_identifier type:string index:skipping -fields: -http_method -http_version type:string index:inverted -fields: -request_uri type:string index:fulltext -fields: -status_code type:int32 -fields: -response_size type:int64 -fields: -timestamp type:time index:timestamp
接着使用 transform 将解析出来的字段保存到数据库中。
❝
transform的语法一目了然,我们将对应的字段和类型进行组合即可;需要注意的是,我们通过
index:为各个字段添加索引;同样,在
timestamp字段上指定index: timestamp,即这个字段被设置为时间索引列。
我们使用如下命令将 Pipeline 配置上传到数据库中,命名为 app_log,并进行保存:
curl -s -XPOST 'http://127.0.0.1:4000/v1/events/pipelines/app_log' -F 'file=@pipeline.yaml'
执行成功后会返回如下 HTTP 响应:
{
"pipelines": [
{
"name": "app_log",
"version": "2025-04-15 07:53:51.914557113"
}
],
"execution_time_ms": 8
}我们也可以在 MySQL 客户端中执行 select name from greptime_private.pipelines; 来确认:
+---------+ | name | +---------+ | app_log | +---------+ 1 row in set (0.005 sec)
更详细的 Pipeline 配置编写规则可以查看官方文档[16]。
❝
注:
GreptimeDB 的 dashboard 上也提供了 Pipeline 配置的在线调试工具,可以使用此文档
http://192.168.31.3:4000/dashboard/#/dashboard/log-pipeline进行调试;如果实在没有头绪,可以尝试请求 AI 来帮助编写 Pipeline 配置 :P(上文的 Pipeline 配置也是作者使用 AI 编写生成的)。
更新 Vector 写入配置
为了使用我们自定义的 Pipeline 配置,需要稍微修改一下 Vector 配置:
# config.toml [sources.file_input] type = "file" include = [ "<path_to_log_dir>/log.txt" ] data_dir = "<data_dir>" ignore_checkpoints = true [sinks.greptime_sink] type = "greptimedb_logs" inputs = [ "file_input" ] compression = "gzip" dbname = "public" endpoint = "http://127.0.0.1:4000" pipeline_name = "app_log" table = "app_log_2"
在 File Source 中添加
ignore_checkpoints = true,让 Vector 可以在每次运行时重新读取相同的文件(此处只是为了调试示例使用);使用我们刚才上传的
app_logPipeline 配置修改pipeline_name = "app_log";修改
table = "app_log_2",我们将新的写入数据保存到另一张表上,避免与刚才的app_log表冲突。
然后再运行 vector -c <path_to_config_file> 即可重新写入日志数据。
在 GreptimeDB 中查询数据
在 MySQL 客户端中运行 show tables; 可以看到 app_log_2 表已经被成功创建了:
+-----------+ | Tables | +-----------+ | app_log | | app_log_2 | | numbers | +-----------+ 3 rows in set (0.008 sec)
我们可以运行 show index from app_log_2; 来观察各字段和索引的情况:
+-----------+------------+----------------+--------------+-----------------+-----------+-------------+----------+--------+------+----------------------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-----------+------------+----------------+--------------+-----------------+-----------+-------------+----------+--------+------+----------------------------+---------+---------------+---------+------------+ | app_log_2 | 1 | SKIPPING INDEX | 1 | client_ip | A | NULL | NULL | NULL | YES | greptime-bloom-filter-v1 | | | YES | NULL | | app_log_2 | 1 | INVERTED INDEX | 3 | http_method | A | NULL | NULL | NULL | YES | greptime-inverted-index-v1 | | | YES | NULL | | app_log_2 | 1 | INVERTED INDEX | 4 | http_version | A | NULL | NULL | NULL | YES | greptime-inverted-index-v1 | | | YES | NULL | | app_log_2 | 1 | FULLTEXT INDEX | 5 | request_uri | A | NULL | NULL | NULL | YES | greptime-fulltext-index-v1 | | | YES | NULL | | app_log_2 | 1 | TIME INDEX | 1 | timestamp | A | NULL | NULL | NULL | NO | | | | YES | NULL | | app_log_2 | 1 | SKIPPING INDEX | 2 | user_identifier | A | NULL | NULL | NULL | YES | greptime-bloom-filter-v1 | | | YES | NULL | +-----------+------------+----------------+--------------+-----------------+-----------+-------------+----------+--------+------+----------------------------+---------+---------------+---------+------------+ 6 rows in set (0.05 sec)
可以看到各个字段的索引也被正确创建了。
然后使用 select * from app_log_2 limit 2; 即可看到如下结果:
+---------------+-----------------+-------------+------------------------------------------+--------------+-------------+---------------+---------------------+ | client_ip | user_identifier | http_method | request_uri | http_version | status_code | response_size | timestamp | +---------------+-----------------+-------------+------------------------------------------+--------------+-------------+---------------+---------------------+ | 17.61.197.240 | nikolaus3107 | HEAD | /envisioneer/efficient | HTTP/1.0 | 406 | 5946 | 2025-04-14 13:11:44 | | 56.87.252.7 | - | PATCH | /bricks-and-clicks/transition/interfaces | HTTP/1.1 | 416 | 15579 | 2025-04-14 13:11:45 | +---------------+-----------------+-------------+------------------------------------------+--------------+-------------+---------------+---------------------+ 2 rows in set (0.008 sec)
可以看到,相较于原本的整个日志行作为一列,现在日志被我们切分成了不同的字段,赋予语义之后单独保存成不同的列。现在我们可以通过类似 where client_id = '17.61.197.240' 的方式对日志进行更精确的匹配查询,这样不仅提高了查询的准确率,也提升了查询的效率。
通过 log-query 查看数据
同样我们可以在 http://127.0.0.1:4000/dashboard/#/dashboard/log-query 中查看 app_log_2 表中的数据,如下图所示:
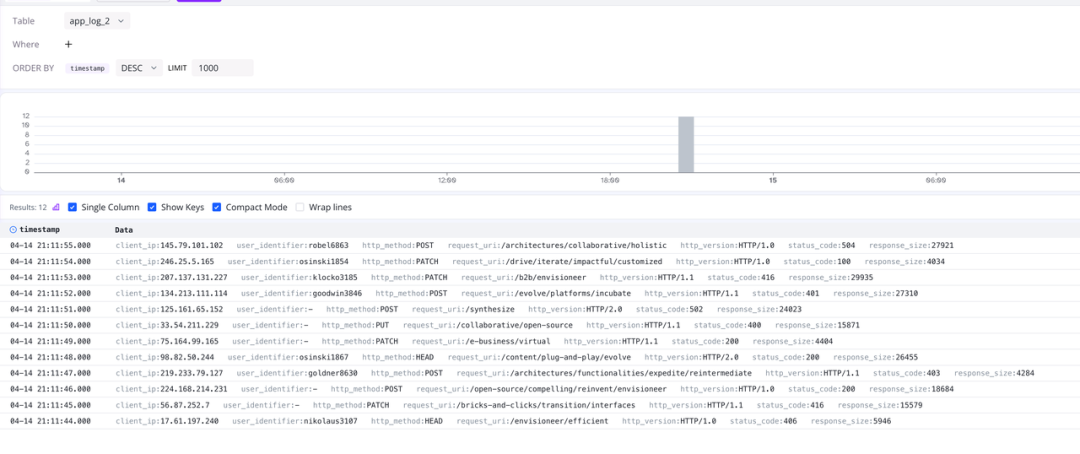
(图 4:查看 app_log_2 表中的数据)
现在对字段进行切分,可以通过 Where 条件在 log-query 上对数据进行快速的过滤,例如:
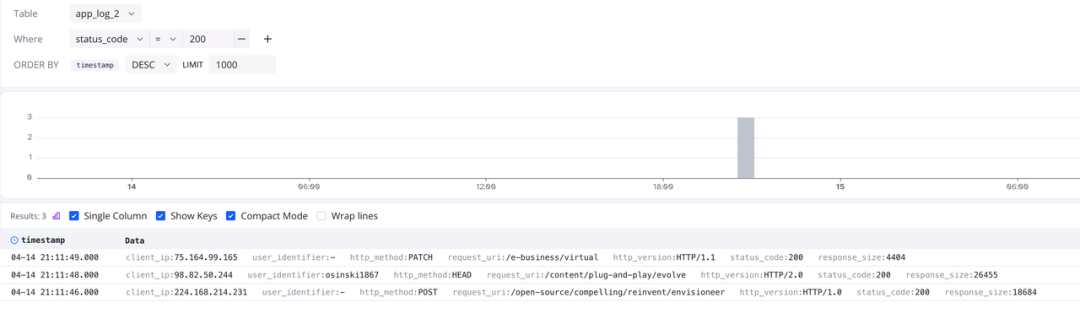
(图 5:快速过滤数据)
总结
本文围绕日志存储展开,分析了 ELK 在当前使用场景下逐渐暴露出的弊端,并介绍了 GreptimeDB 作为新一代日志数据库在架构和使用体验上的优势。通过 Vector + GreptimeDB 的组合,我们展示了日志从采集到存储、再到解析和查询的完整流程。
在查询环节,我们演示了使用 MySQL 客户端以及 GreptimeDB 自带的 log-query 工具进行数据检索。作为一个开源、兼容性强的时序数据库,GreptimeDB 也支持与 Grafana 等可视化工具无缝集成,帮助用户轻松实现日志的分析与展示。
如果你对日志处理感兴趣,欢迎根据本文提供的示例进一步修改配置,探索更加灵活高效的日志方案。
Reference
[1] https://www.elastic.co/docs/reference/beats
[2] https://docs.greptime.com/nightly/user-guide/administration/design-table/#index
[3] https://github.com/mingrammer/flog
[4] https://vector.dev/docs/reference/configuration/sources/kubernetes_logs/
[5] https://docs.greptime.com/nightly/user-guide/deployments/deploy-on-kubernetes/overview/
[6] https://docs.greptime.com/nightly/getting-started/installation/greptimedb-standalone/
[7] https://vector.dev/docs/setup/installation/
[8] https://vector.dev/docs/setup/installation/package-managers/
[9] https://greptime.cn/blogs/2024-12-11-vector-kubernetes
[10] https://vector.dev/docs/reference/configuration/sources/file/
[11] https://vector.dev/docs/reference/configuration/sources/file/#include
[12] https://vector.dev/docs/reference/configuration/sinks/greptimedb_logs/
[13] https://docs.greptime.com/user-guide/logs/pipeline-config
[14] https://docs.greptime.com/user-guide/logs/manage-pipelines/#greptime_identity
[15] https://docs.greptime.com/nightly/user-guide/logs/manage-pipelines#specify-time-index
[16] https://docs.greptime.com/nightly/user-guide/logs/pipeline-config/

 成员
成员 - 成交数 --
- 成交额 --
- 应答率